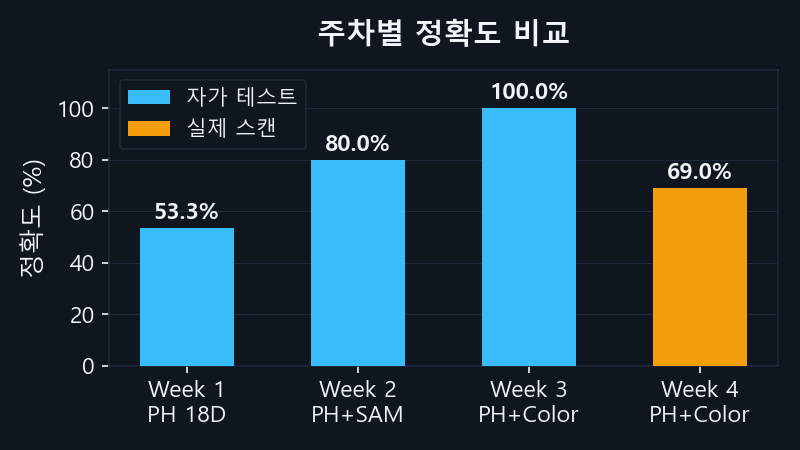
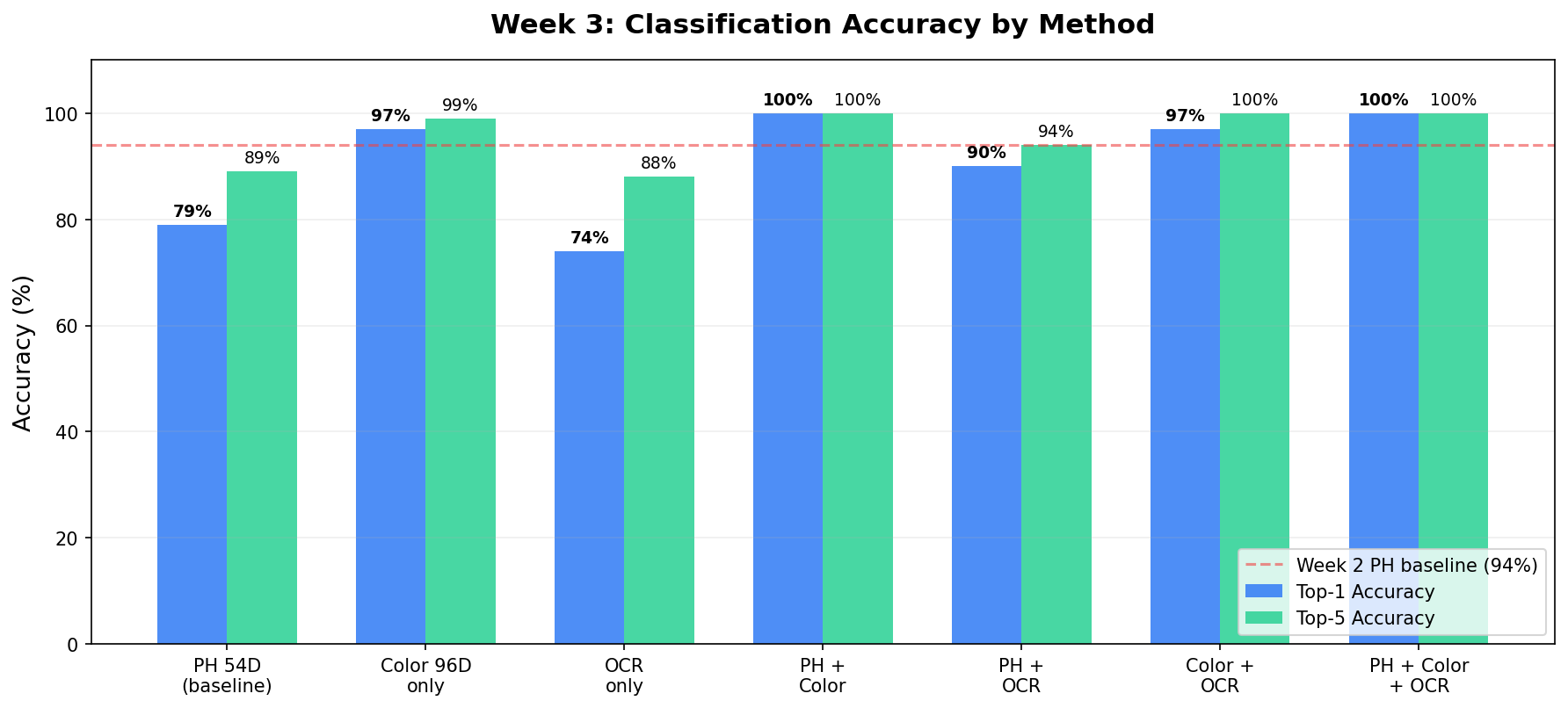
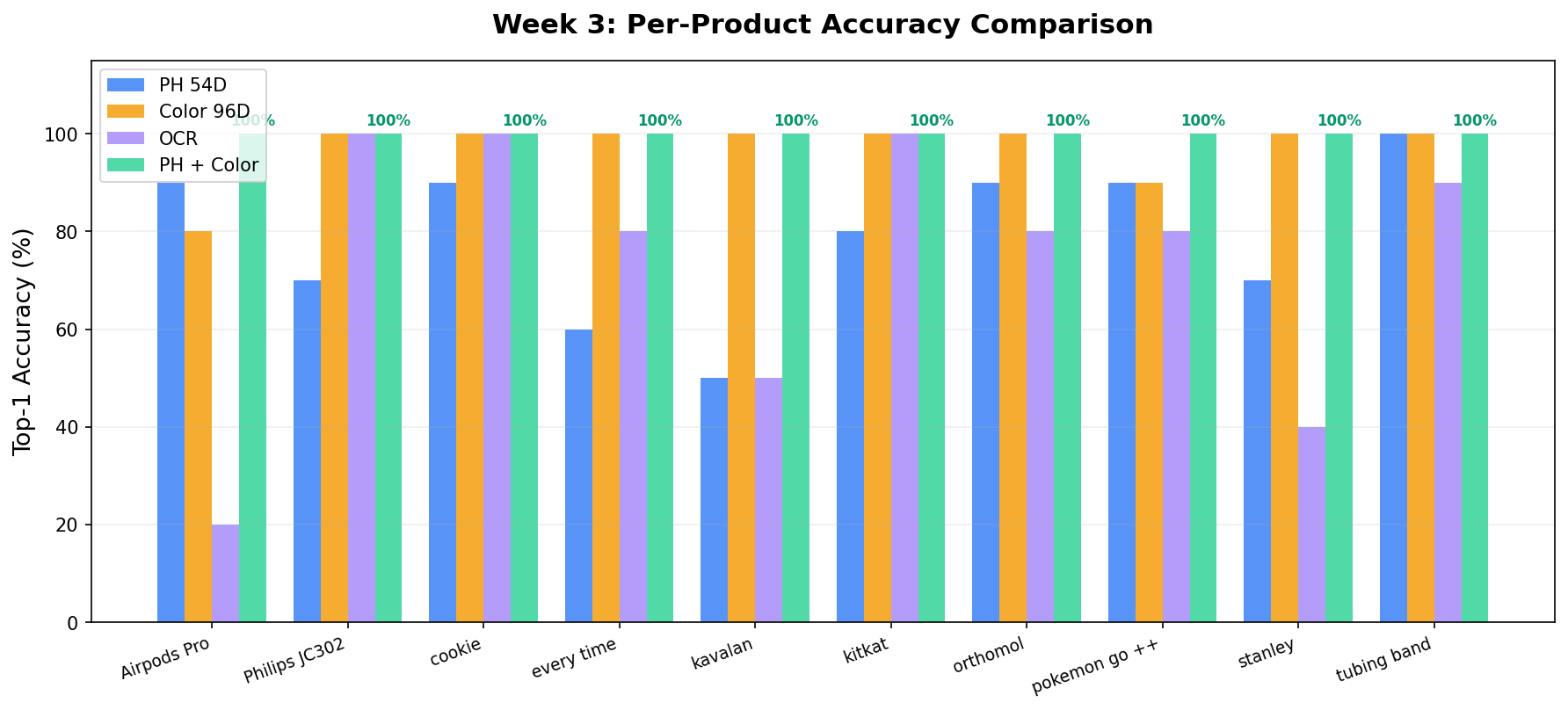
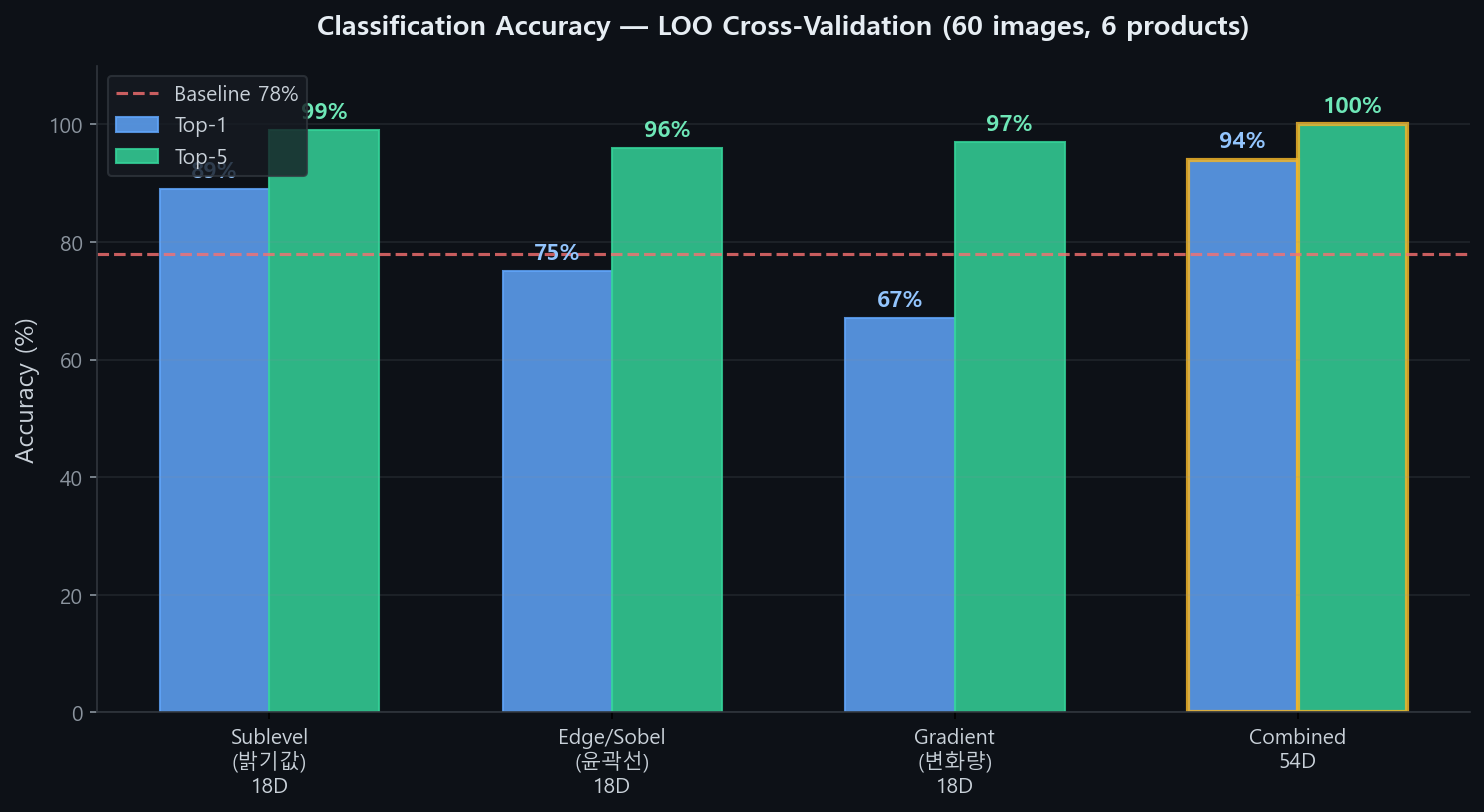
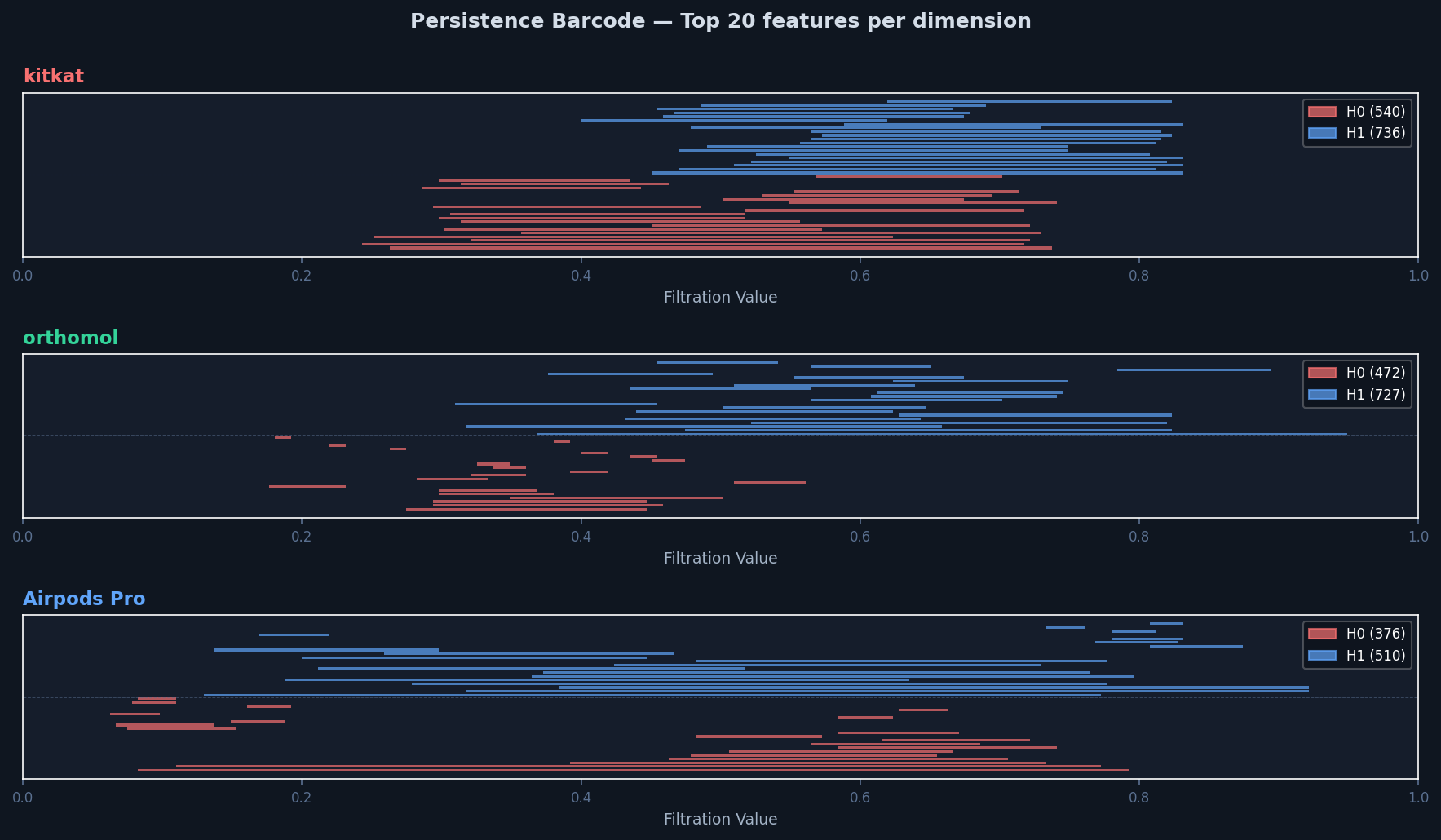
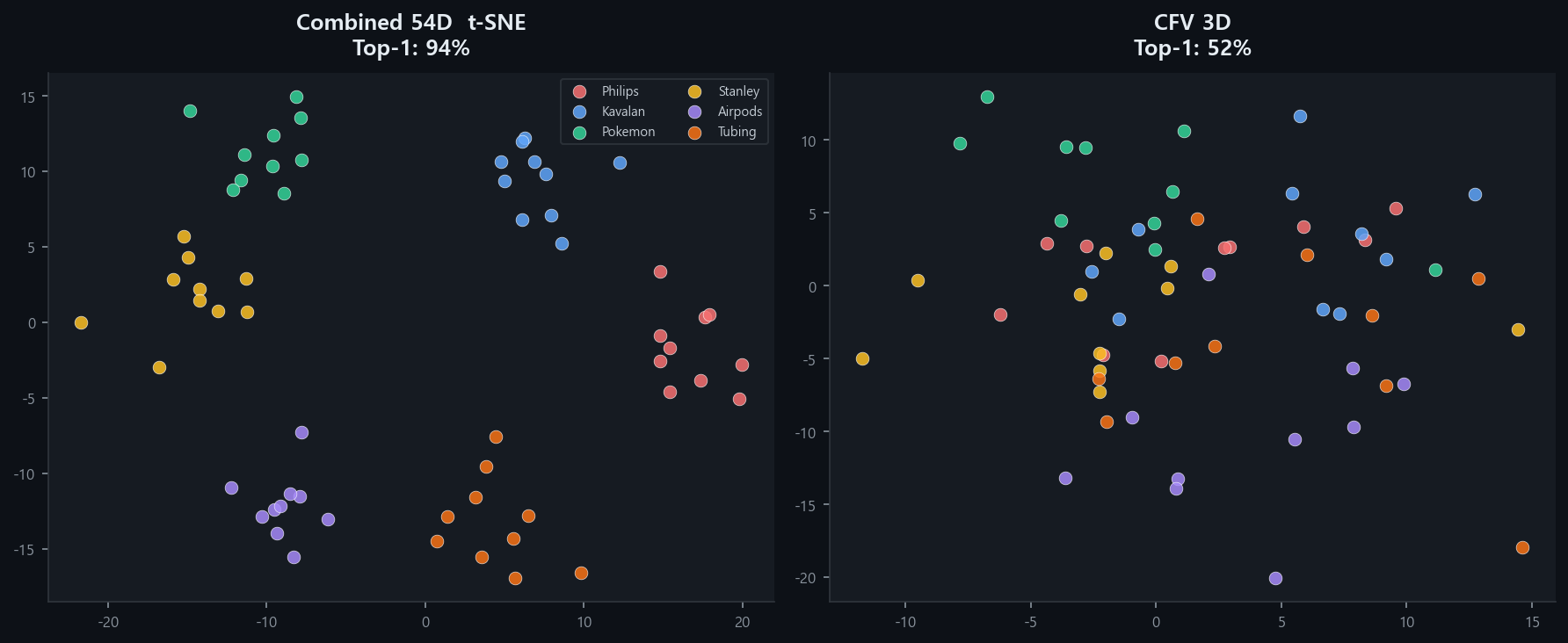
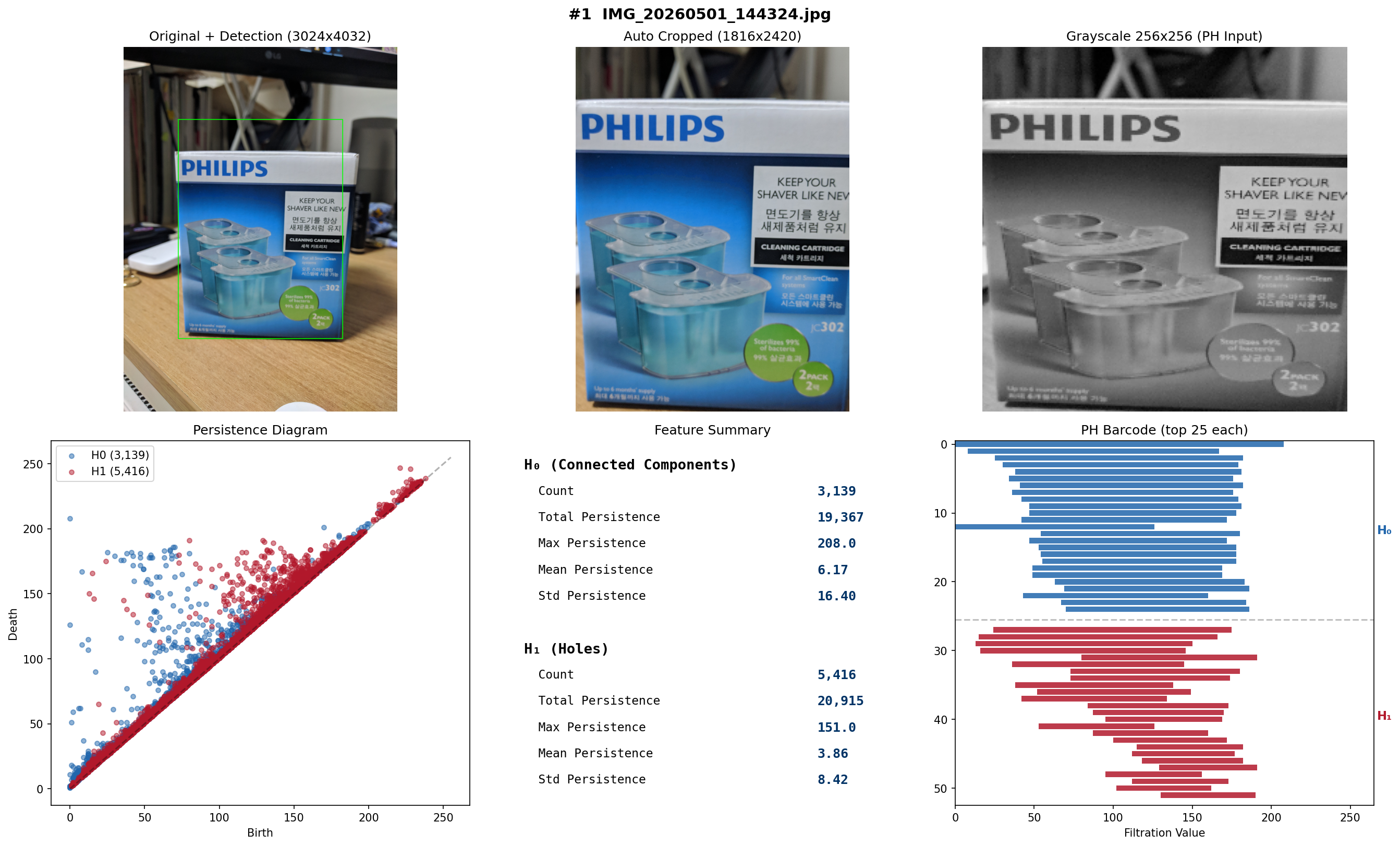
3주차에서 자가 테스트(DB 이미지 ↔ DB 이미지) 100%를 달성하였으나, 이는 등록된 이미지로 등록된 이미지를 찾는 것이다.
4주차에서는 등록모드(PH+Color+OCR로 상품 정보 저장)와 스캔모드(카메라로 실물을 촬영하여 판정)를 분리하고,
SAM을 제거하고 center_crop으로 통일한 뒤, 실제 스마트폰으로 10종 상품을 스캔하여 정확도를 측정하였다.
등록모드 / 스캔모드 분리
등록모드 — Product Registration
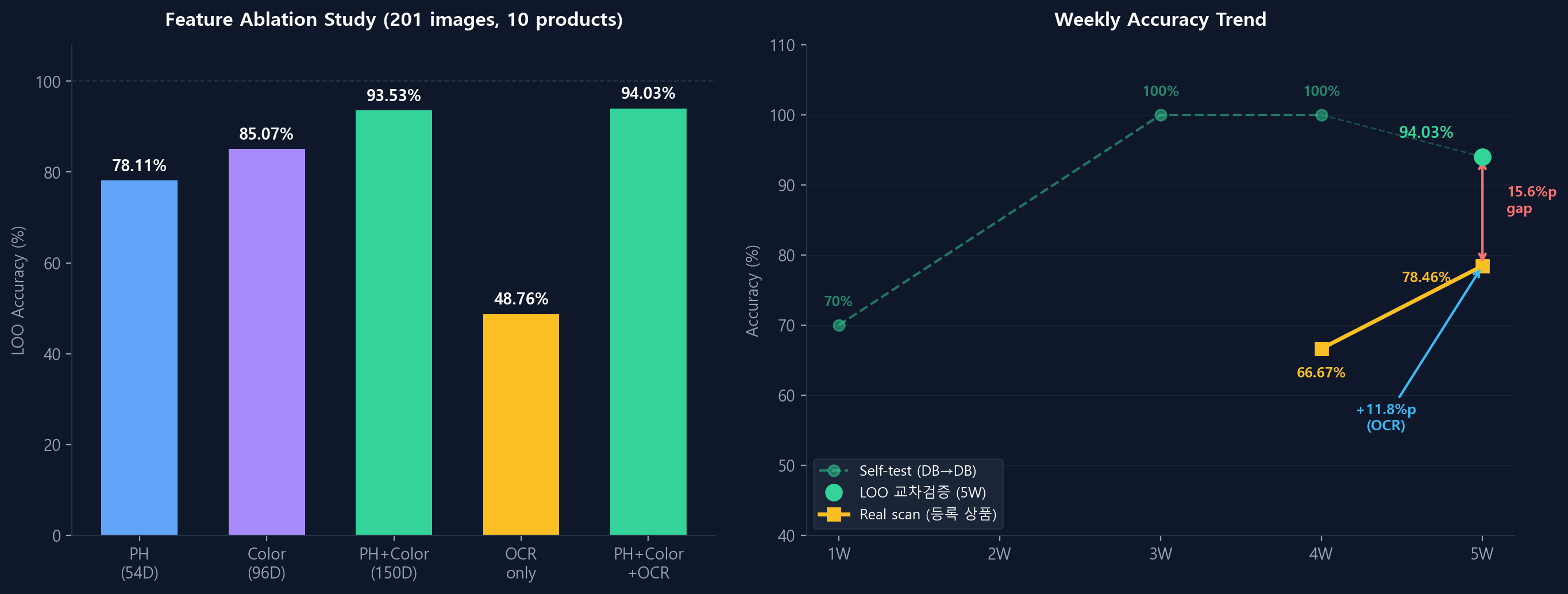
PH 54D + Color 96D + OCR
상품 사진을 서버에 업로드하면
PH(형태) + Color(색상) + OCR(글자) 세 가지 피처를
모두 계산하여 DB에 저장한다. ~8초/장.
스캔모드 — Product Scan
PH 54D + Color 96D (OCR 제외)
카메라로 상품을 비추면 2초 간격으로
PH+Color만 추출하여 DB와 비교한다.
OCR 제외로 ~700ms에 응답.
SAM 제거 → center_crop 통일
이전 주차에서는 등록 시 MobileSAM(물체 인식 크롭)을 사용했으나, 스캔 시에는 SAM 없이 center_crop을 사용했다.
SAM 크롭과 center_crop이 만드는 이미지가 다르기 때문에 — 같은 상품을 찍어도
피처 벡터가 완전히 다른 공간에 놓이는 문제가 발생하였다 (PH L2 차이: 5,267).
등록과 스캔 모두 center_crop(3:4 비율 중앙 크롭)으로 통일하여 피처 공간 불일치를 해결하였다.
Z-score 정규화
3주차에서는 Min-Max 정규화를 사용했다. 그러나 Min-Max는 쿼리마다 최소/최대가 바뀌어 결과가 불안정하다.
4주차에서 Z-score 정규화로 전환하여 DB 전체의 평균(μ)과 표준편차(σ)를 기준으로 정규화한다.
Min-Max (3주차)
(x - min) / (max - min)
쿼리마다 min/max가 달라져 상대적 → 86.7%
Z-score (4주차)
(x - μ) / σ
DB 전체 통계 기준으로 고정 → 100%
자가 테스트 vs 실제 스캔
자가 테스트는 DB에 등록된 이미지를 다시 쿼리로 넣는 것이다. 같은 이미지이므로 100%가 당연하다.
실제 스캔은 스마트폰 카메라로 실물 상품을 촬영한다. 조명, 각도, 거리, 배경이 모두 달라진다.
이 차이가 정확도 100% → 69.0% 하락의 원인이다.
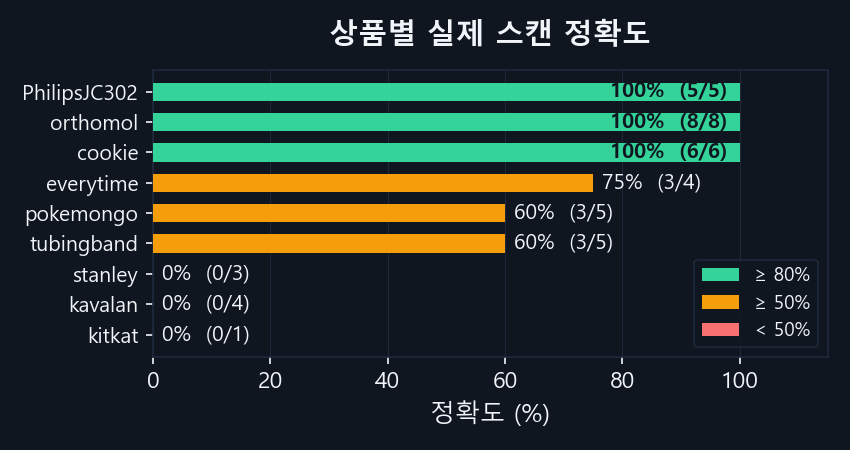
상품별 실제 스캔 정확도
| Product | 스캔 | 정답 | 정확도 | 주요 오판 |
|---|
| PhilipsJC302 | 5 | 5 | 100% | — |
| orthomol | 8 | 8 | 100% | — |
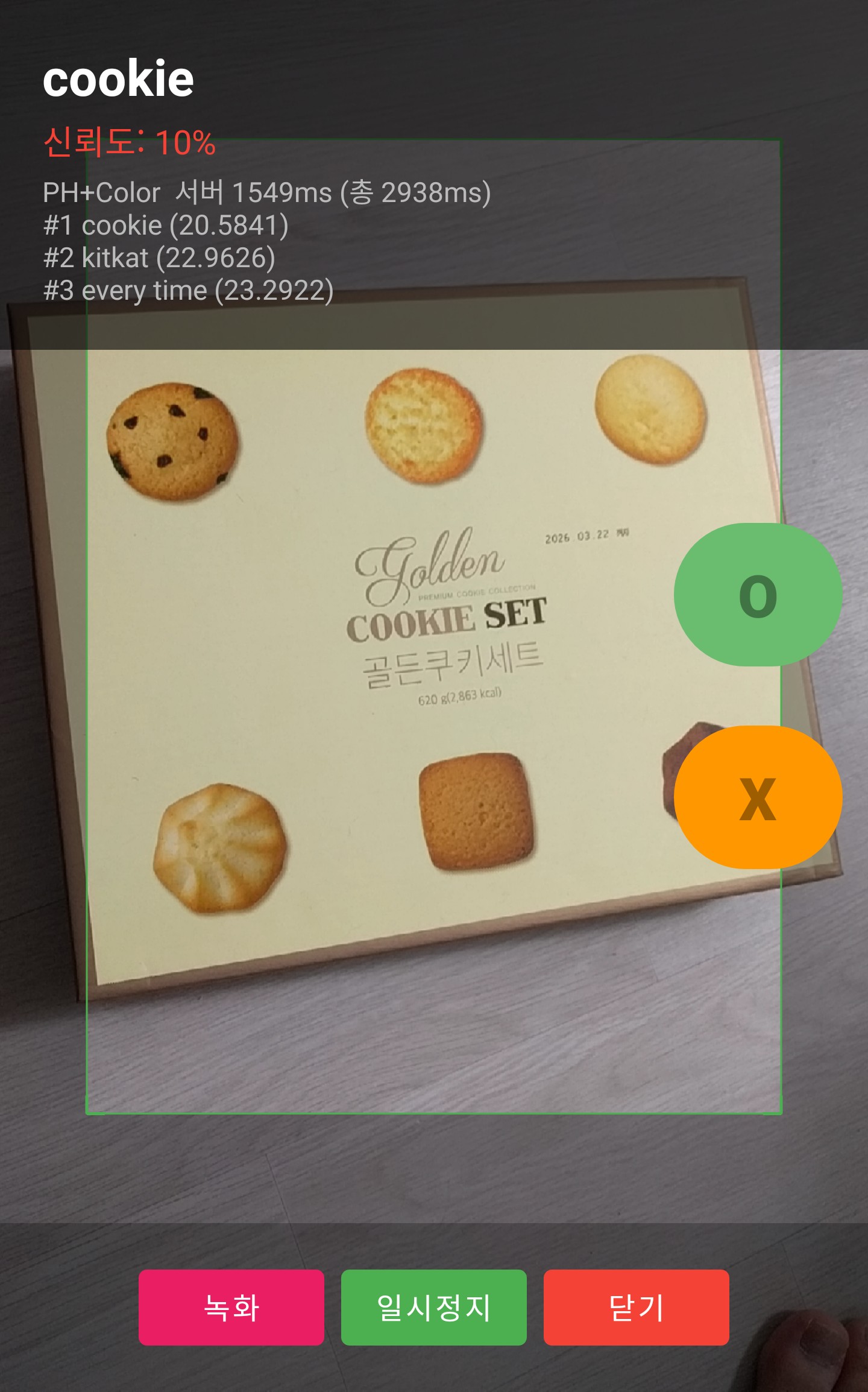
| cookie | 6 | 6 | 100% | — |
| every time | 4 | 3 | 75% | → kitkat ×1 |
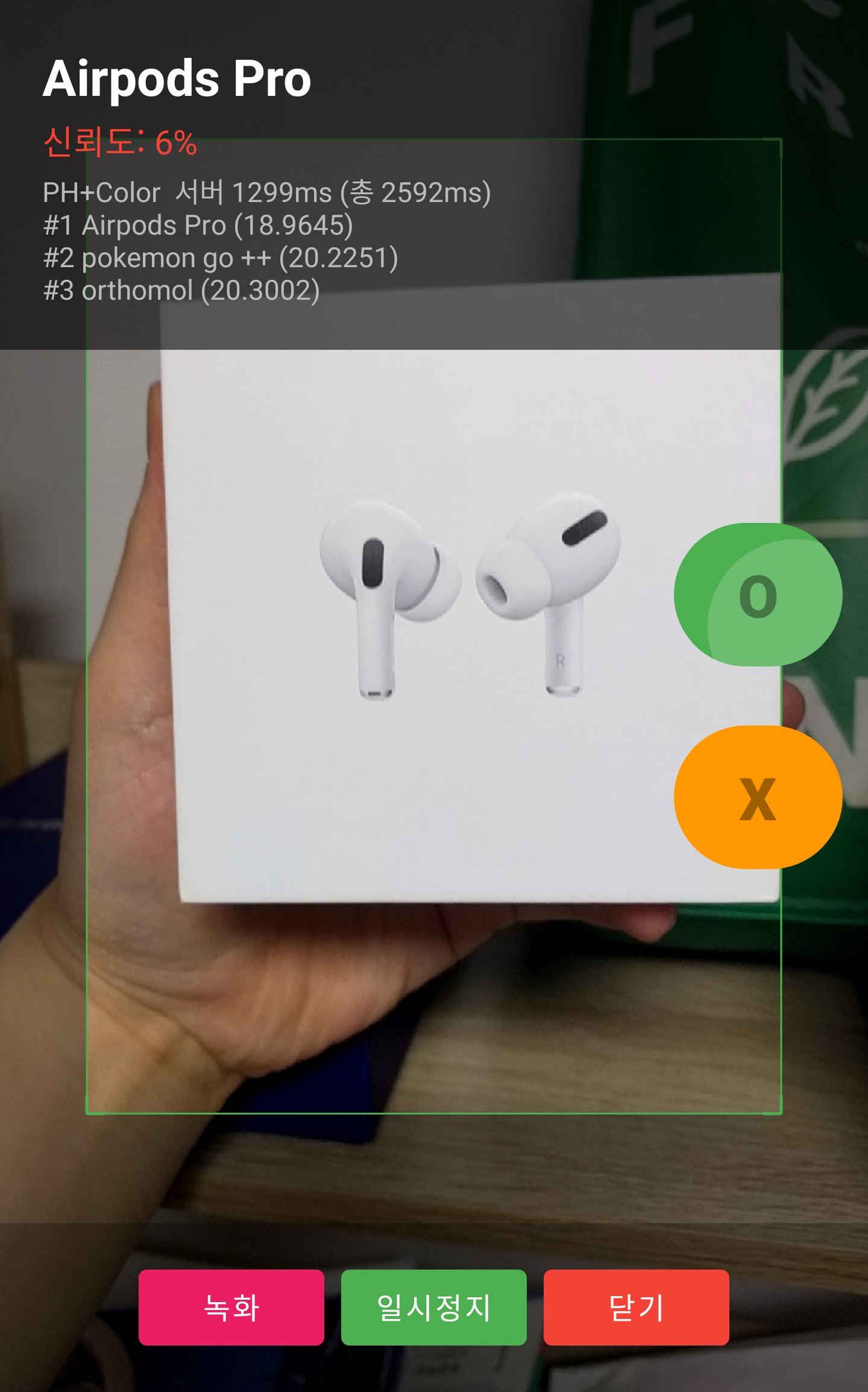
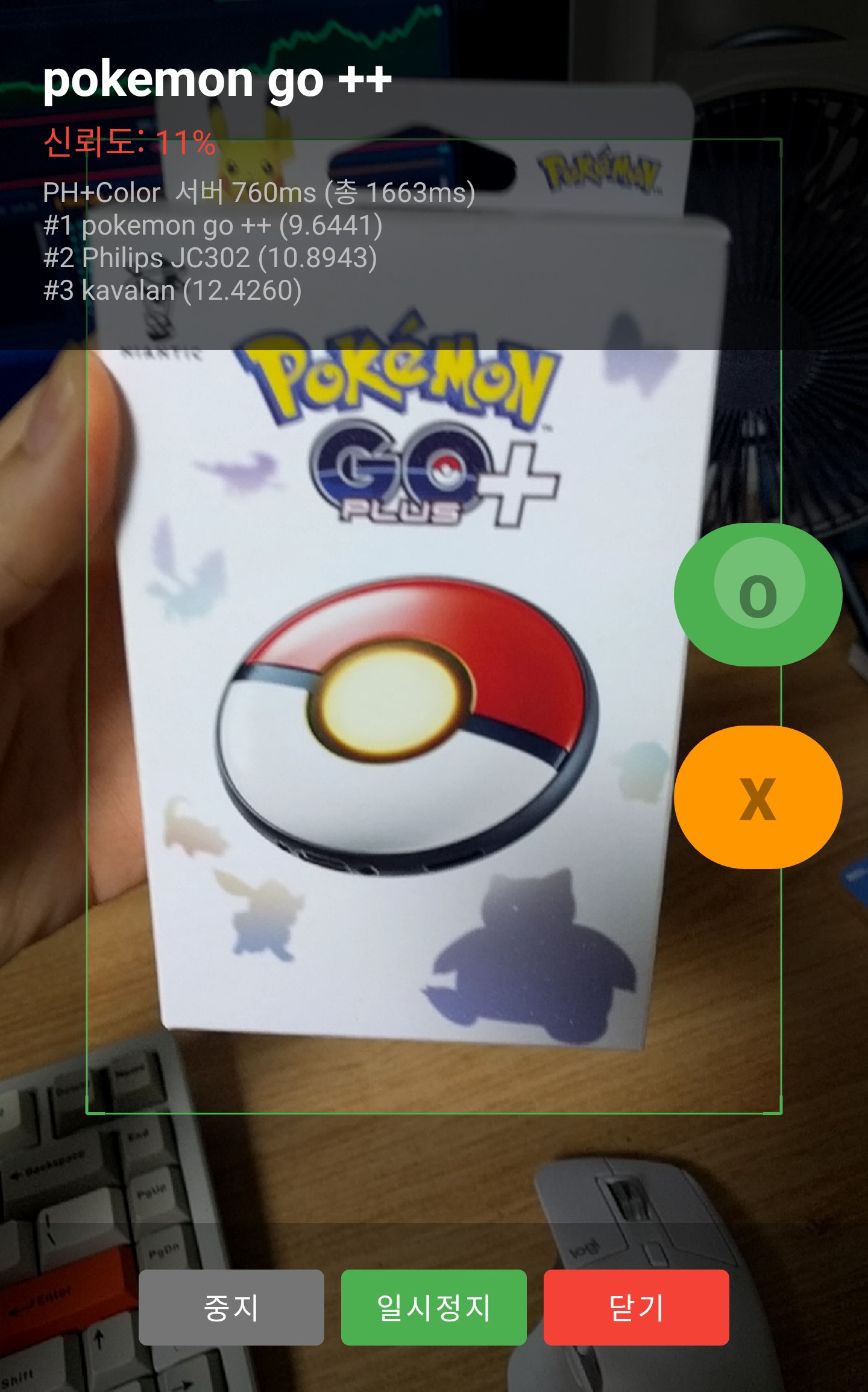
| pokemon go | 5 | 3 | 60% | → PhilipsJC302 ×2 |
| tubing band | 5 | 3 | 60% | → kavalan ×2 |
| stanley | 3 | 0 | 0% | → every time ×3 |
| kavalan | 4 | 0 | 0% | → every time ×3, kitkat ×1 |
| kitkat | 1 | 0 | 0% | → every time ×1 |
| 정답없음 (미등록) | 3 | 0 | — | pokemongo, kitkat, everytime으로 오분류 |
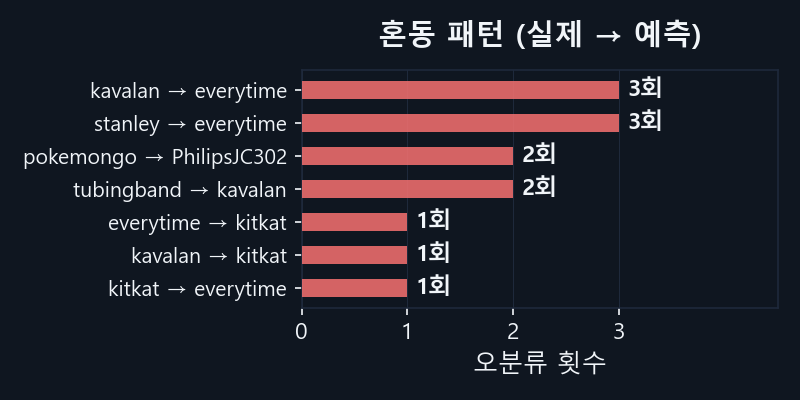
혼동 패턴 분석
오판이 특정 상품 쌍에 집중된다. stanley → every time (3회), kavalan → every time/kitkat (4회), tubingband → kavalan (2회).
every time이 강한 어트랙터로 작용하여, stanley·kavalan·kitkat이 모두 every time으로 끌린다.
PH+Color 만으로는 이 유사성을 구분하지 못한다 — 텍스트(OCR)가 구분의 열쇠가 될 수 있다.
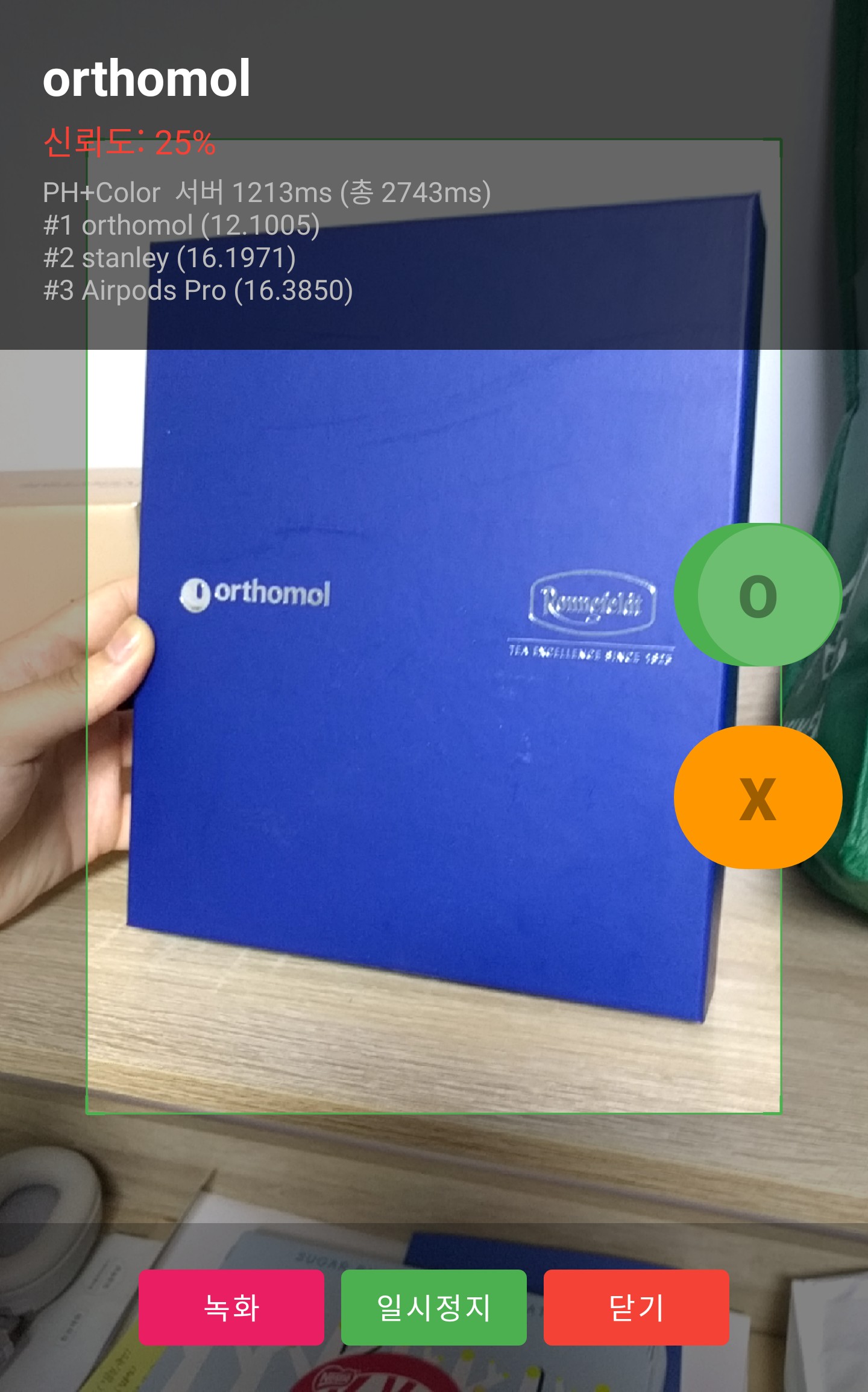
실제 스캔 화면
Android 앱의 스캔모드에서 실제 상품을 카메라로 비추고, O(정답)/X(오답) 버튼으로 판정한 결과이다.
상단에 예측 상품명과 신뢰도, 하단에 Top-3 매칭 결과와 서버 응답 시간이 표시된다.
정답 사례 (O) — 대표 6건correct
오답 사례 (X) — 대표 4건wrong
신뢰도(Confidence)란
신뢰도는 1위와 2위의 거리 차이를 나타낸다: confidence = (d₂ - d₁) / d₂
값이 클수록 1위가 확실히 가깝고, 작으면 1위와 2위가 비슷하다는 뜻이다.
실제 결과에서 정답도 오답도 대부분 0.002~0.17 범위로 낮았다 —
상품 간 거리가 전반적으로 비슷하여 신뢰도만으로 정답/오답을 구분하기 어렵다.
4주차 결론
자가 테스트 100%와 실제 스캔 69.0%의 차이는 카메라 촬영 환경의 변동성(조명, 각도, 거리)이 원인이다.
등록된 이미지는 고정된 조건에서 촬영되었지만, 실제 스캔은 매번 다른 조건에서 촬영된다.
9개 상품 중 3개(PhilipsJC302, orthomol, cookie)가 100%를 달성했지만,
stanley(0%), kavalan(0%), kitkat(0%)에서 전혀 인식에 실패하였고, every time(75%), pokemongo·tubingband(60%)도 불완전하다.
그러나 랜덤(10%) 대비 PH+Color(69.0%)는 의미 있는 개선이며,
PH 피처(위상적 형태 정보)가 색상 정보와 결합하여 식별력에 기여한다는 근거가 된다.
every time이 어트랙터로 작용하여 stanley·kavalan·kitkat을 끌어당기는 패턴이 확인되었으며,
텍스트가 뚜렷한 상품의 혼동은 OCR 추가가 해소의 열쇠가 될 수 있다.
4주차 시행착오log
- SAM ↔ center_crop 피처 불일치 — 등록(SAM)과 스캔(center_crop)의 크롭 영역이 달라 피처 벡터가 완전히 다른 공간에 놓였다. PH L2 차이 5,267. center_crop 통일로 해결.
- Min-Max → Z-score 정규화 — Min-Max는 쿼리마다 기준이 바뀌어 86.7%. Z-score(DB 전체 통계 고정)로 전환 후 100%.
- Color Histogram 불일치 — 쿼리는 H/S/V 분리 32bin, DB는 HSV joint [8,8,2]로 계산. H32+S32+V32 = 96D로 통일.
- OCR 해상도 — 256px 리사이즈 시 OCR이 무의미한 결과("fi ss", "bw"). 원본 해상도에서 의미 있는 텍스트 추출 확인("sugar butter tree kit"). 등록모드에서만 원본 해상도 OCR 수행.
- result_summary 컬럼 오버플로우 — TEXT(64KB) 제한으로 OCR이 긴 이미지에서 저장 실패. MEDIUMTEXT로 변경.
다음 주 계획
- 스캔모드에 OCR 추가 검토 — OCR이 ~6초 걸려 스캔에서 제외했으나, kavalan↔every time 혼동을 OCR로 해소할 수 있는지 검증. OCR 경량화(해상도 조정, 엔진 교체) 또는 비동기 처리 방식을 탐색한다.
- PH+Color vs PH+Color+OCR 정량 비교 — 동일 스캔 세트에서 OCR 유무에 따른 정확도를 비교하여, OCR의 실질적 기여도를 정량적으로 확인한다.
- 혼동 상품 쌍 심층 분석 — kavalan/every time, pokemon go/tubing band의 피처 벡터를 시각화하여, 어떤 차원에서 혼동이 발생하는지 분석한다.
사용 도구 (모두 오픈소스)tools
| 용도 | 도구 | 버전 | 라이선스 |
|---|
| PH 계산 | GUDHI | 3.12.0 | MIT |
| 이미지 처리 + Color Histogram | OpenCV | 4.13.0 | Apache 2.0 |
| OCR 엔진 (등록모드) | Tesseract | 5.5.0 | Apache 2.0 |
| Android 앱 | CameraX + Retrofit 2 | — | Apache 2.0 |
| 서버 | Spring Boot + MySQL | 3.5 / 8.4 | Apache / GPL |